Draining a Node Should Reschedule Pods Quickly
Draining a Node Should Reschedule Pods Quickly
Draining a Node Should Reschedule Pods Quickly
Draining a Node Should Reschedule Pods Quickly
When draining a node, Kubernetes should reschedule running pods on other nodes without hiccups to ease, e.g., node maintenance.
Motivation
Draining a node may be necessary for, e.g., maintenance of a node. If that happens, Kubernetes should be able to reschedule the pods running on that node within the expected time and without user-noticeable failures.
Structure
For the entire duration of the experiment, a user-facing endpoint should work within expected success rates. At the beginning of the experiment, all pods should be ready to accept traffic. As soon as the node is drained, Kubernetes will evict the pods, but we still expect the pod's redundancy to be able to serve the user-facing endpoint. Eventually, after 120 seconds, all pods should be rescheduled and ready again to recover after the maintenance.
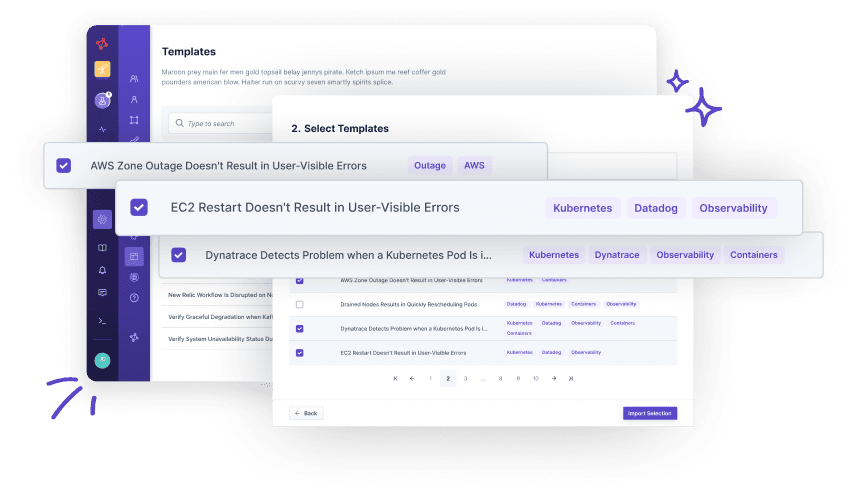
How to use this template?
Import via Hub Connection
Steadybit’s Reliability Hub is already connected to your platform. If you are an admin, you can just easily import templates with just one click.
Are you on-prem?
This is how you import Templates